type
status
date
slug
summary
tags
category
icon
password
堆数组中第k个最大元素解法:使用分治思想前 K 个高频元素解法1:使用map的value排序解法2:使用小顶堆295. 数据流的中位数栈每日温度解法:单调栈柱状图中最大的矩形解法:单调栈贪心算法跳跃游戏45. 跳跃游戏 II解法:搭桥算法763. 划分字母区间解法:合并区间解法:合并区间极简做法回溯全排列解法一:全排列型回溯:利用布尔数组解法二:全排列型回溯:利用Set子集解法:灵神的回溯模版之一: 子集回溯模版解法二:代码随想录思路(喜欢这个)电话号码的字母组合解法:两个不同数组的回溯39. 组合总和解法:关于去除排列顺序的组合问题括号生成解法:组合回溯模版:选或不选:单词搜索解法:图DFS + 回溯回文字符串解法一:子集回溯:选或不选 解法二:子集回溯:枚举选哪个N皇后解法:全排列回溯DP爬楼梯打家劫舍解法一:使用递归来做解法二:使用递推解法三:动态规划完全平方数解法:记忆化递归零钱兑换解法:记忆化递归法单词拆分最长递增子序列解法
堆
数组中第k个最大元素
给定整数数组
nums 和整数 k,请返回数组中第 k 个最大的元素。请注意,你需要找的是数组排序后的第
k 个最大的元素,而不是第 k 个不同的元素。你必须设计并实现时间复杂度为
O(n) 的算法解决此问题。示例 1:
示例 2:
提示:
1 <= k <= nums.length <= 105
104 <= nums[i] <= 104
解法:使用分治思想
前 K 个高频元素
给你一个整数数组
nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。示例 1:
示例 2:
解法1:使用map的value排序
解法2:使用小顶堆
295. 数据流的中位数
中位数是有序整数列表中的中间值。如果列表的大小是偶数,则没有中间值,中位数是两个中间值的平均值。
- 例如
arr = [2,3,4]的中位数是3。
- 例如
arr = [2,3]的中位数是(2 + 3) / 2 = 2.5。
实现 MedianFinder 类:
MedianFinder()初始化MedianFinder对象。
void addNum(int num)将数据流中的整数num添加到数据结构中。
double findMedian()返回到目前为止所有元素的中位数。与实际答案相差105以内的答案将被接受。
示例 1:
提示:
105 <= num <= 105
- 在调用
findMedian之前,数据结构中至少有一个元素
- 最多
5 * 104次调用addNum和findMedian
栈
每日温度
给定一个整数数组
temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。示例 1:
示例 2:
示例 3:
提示:
1 <= temperatures.length <= 105
30 <= temperatures[i] <= 100
解法:单调栈
柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:
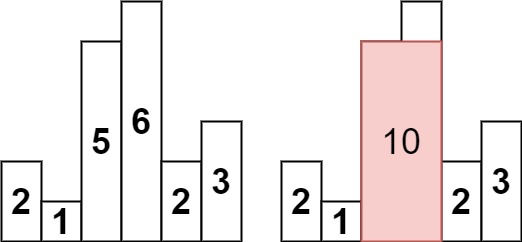
示例 2:
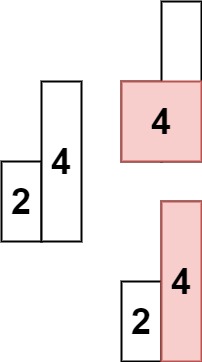
提示:
1 <= heights.length <=105
0 <= heights[i] <= 104
解法:单调栈
单调栈针对:
- 需要求出当前项的前一个(后一个)最大(最小)值的情形
- 这里是找出左边和右边第一个小于当前idx的height
贪心算法
跳跃游戏
给你一个非负整数数组
nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个下标,如果可以,返回
true ;否则,返回 false 。示例 1:
示例 2:
提示:
1 <= nums.length <= 104
0 <= nums[i] <= 105
45. 跳跃游戏 II
给定一个长度为
n 的 0 索引整数数组 nums。初始位置为 nums[0]。每个元素
nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:0 <= j <= nums[i]
i + j < n
返回到达
nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。示例 1:
示例 2:
提示:
1 <= nums.length <= 104
0 <= nums[i] <= 1000
- 题目保证可以到达
nums[n-1]
解法:搭桥算法
这个算法注意:
- 遍历只需要遍历到n-2,这是因为搭桥这个动作再最后一个元素上是做不出来的
- 针对顺序问题,应该是先搭桥,再走桥(更新当前桥,步数+1)
763. 划分字母区间
给你一个字符串
s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。例如,字符串 "ababcc" 能够被分为 ["abab", "cc"],但类似 ["aba", "bcc"] 或 ["ab", "ab", "cc"] 的划分是非法的。注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是
s 。返回一个表示每个字符串片段的长度的列表。
示例 1:
示例 2:
提示:
1 <= s.length <= 500
s仅由小写英文字母组成
解法:合并区间
解法:合并区间极简做法
- 只关注右区间
回溯
全排列
给定一个不含重复数字的数组
nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。示例 1:
示例 2:
示例 3:
解法一:全排列型回溯:利用布尔数组
- 在全排列回溯中,重点是要维持一个变量来保存目前还剩那些参数可以放进path
- 同时要注意:
- for循环是从0开始,因为不是子集型排列,不需要去除重复元素
- 每次for循环步骤:
- 先进行对path的添加
- 再修改布尔数组
- 开始回溯
- 恢复两者现场
解法二:全排列型回溯:利用Set
学习之处:
- 回溯这个算法,说白了就是将很多for循环放在了
dfs(i+1)这一层继续循环 - 如果不考虑灵神的选或不选算法的话
- 但我发现我还是喜欢用代码随想录的思路,直接进行for遍历,选一次进行一次
dfs(i+1)
子集
给你一个整数数组
nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
示例 2:
提示:
1 <= nums.length <= 10
10 <= nums[i] <= 10
nums中的所有元素 互不相同
解法:灵神的回溯模版之一: 子集回溯模版
灵神的子集回溯模版是真的好用,并且思路也非常易懂
这里给出例子:
首先给出code代码
可以注意到这非常的简洁:
- 将一些变量进行全局化,比如说
ans和path,方便函数进行使用,对于函数的参数nums也可以全局化,这样在backTrace中也能进行调用
- 回溯函数
backTrace - 对于这种子集性回溯,可以用
取 or 不取的思路 - 在代码中写出来就是这样:
- 因为最开始不选,所以
backTrace(n + 1);前后什么都没有 - 对于选择的情况,才会进行放入path以及恢复path
- 最后才进行边界条件:
- 将path放入ans中

- 当然,在
选或不选中,两者的顺序是可以改变的
解法二:代码随想录思路(喜欢这个)
但就像刚刚所说,这种比较灵活的算法对我的脑子不是很友好,所以这里写一个比较不是很动脑子的解法
- 这个算法就是所说的,利用的是回溯就是多次for循环的变种,这个思路
电话号码的字母组合
给定一个仅包含数字
2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。

示例 1:
示例 2:
示例 3:
解法:两个不同数组的回溯
对于这种在两个或者多个数组中进行组合的情况,思路和前两个一样,都是对for循环的进一步利用
- 每次的
dfs函数针对的是复数数组的其中一个数组
- 在一个数组中间进行遍历和恢复现场
39. 组合总和
给你一个 无重复元素 的整数数组
candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。对于给定的输入,保证和为
target 的不同组合数少于 150 个。示例 1:
示例 2:
示例 3:
提示:
1 <= candidates.length <= 30
2 <= candidates[i] <= 40
candidates的所有元素 互不相同
1 <= target <= 40
解法:关于去除排列顺序的组合问题
这种类型的题目,和上面的for循环题目的唯一区别就是注意for循环中的起始点,我们需要手动设置for循环中的起始循环位置,这样就可以把结果相同但是顺序不同的状态去除掉
注意:
- 如果
dfs(leftSum - candidates[i], target, candidates, i);被改为dfs(leftSum - candidates[i], target, candidates, i + 1);这就代表不能取相同的数字在path中,如果遇到类似的题目需要注意
括号生成
数字
n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。示例 1:
示例 2:
提示:
1 <= n <= 8
解法:组合回溯模版:选或不选:
这题能够用灵神的选或不选模版,让我对这个模版的印象更深了
- 将问题转化为:在长度为
2*n的数组中,选择或者不选择左括号放入第i项 - 为什么是左括号?
- 因为题目条件隐含约束:在每次进行放入的时候,左括号要大于等于右括号
- 同时左括号的个数不能大于n
- 进行选或不选操作:
- 每选择其中一种,就进入下一个递归中,选择下一个数
- 顺序可以交换,思路比较简单,很喜欢
单词搜索
给定一个
m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
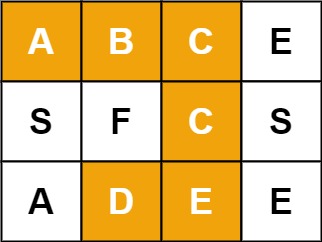
示例 2:

示例 3:

解法:图DFS + 回溯
刚刚讲的图DFS方法就是这道题必然会用到的方法,在本题中的主题逻辑:
- 在主函数先进行两层for循环进行遍历,找寻入口
- 如果找到符合条件的第一个参数,进入
dfs函数
- 在
dfs函数中 - 首先判断,如果
i和j坐标超出范围,或者当前坐标指向的值不对应,则返回false - 然后将当前值进行覆盖
- 本题中是覆盖为0,这样不会让正在深度搜索的程序开始走回头路
- 这里的回头路是指避免a - > b - > a这种问题
- 开始进行上下左右的DFS
- 进行
if(dfs(…)),如果条件返回true,本次dfs也返回true - 如果都没有返回true,那就返回false
- 编程技巧:
- 使用
direction作为方向判断,在更新i和j的时候重新赋值x和y,非常方便 - 将word反转,直接使用
Stringbuffer的reverse函数,生成一个新的string
注意:
- 需要避免搜索走回头路,所以还是需要进行路径的标记,把走过的路标记后,不能继续进行走
- 有点像是全标记后的感觉
python版本:
回文字符串
给你一个字符串
s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。示例 1:
示例 2:
提示:
1 <= s.length <= 16
s仅由小写英文字母组成
解法一:子集回溯:选或不选
按照上面讲的子集回溯类型,这里可以将一个字符串看做
第i个字符后的逗号是否要选择- 一直不选,但是在倒数第二字符必须要选择,不然就导致是空字符串了, 但是题目要求中必须是有字符串的
- 开始选:
- 因为一旦选择成功了,本来的回文字符串在本轮就不用考虑了,所以
start直接更新在n的位置
解法二:子集回溯:枚举选哪个
这个和之前在代码随想录中写的是差不多一样的,背下来就好,大多数情况都可以用
- 每同一层for循环都是搜索树的一层
- 在进入递归后进入了下一层
- 果然我还是喜欢这个!!!!
N皇后
按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将
n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。给你一个整数
n ,返回所有不同的 n 皇后问题 的解决方案。每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中
'Q' 和 '.' 分别代表了皇后和空位。示例 1:
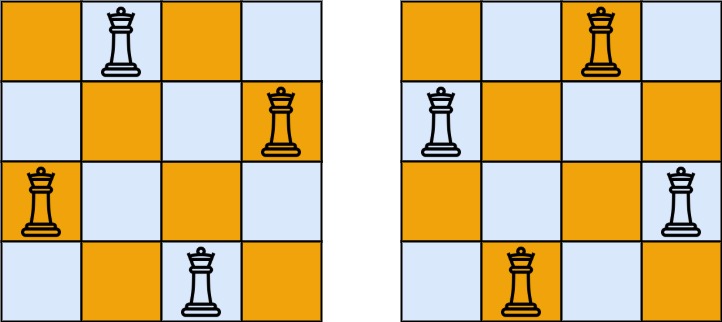
示例 2:
提示:
1 <= n <= 9
解法:全排列回溯
可以知道,N皇后是每行每列只有一个,那么我们可以把它看做是n个数的全排列问题
- 构建一个col数组,皇后在每行的位置就存入col数组中
- 例如:例子一中的情形就是:
- [1, 3, 0 ,2]
- [2, 0, 3, 1]
- 存储长度为n的set,用来保存每次进行排列时候还能选取的数
- 开始进行全排列操作,不过此次全排列需要经过一些约束条件:
- 此行之前的行中,皇后的位置,横纵坐标上
- Row + Col不能等于当前的r + c
- Row - Col 不能等于当前的 r - c
- 经过此判断条件之后,才能进行元素选取
DP
爬楼梯
假设你正在爬楼梯。需要
n 阶你才能到达楼顶。每次你可以爬
1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?示例 1:
打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
示例 2:
提示:
1 <= nums.length <= 100
0 <= nums[i] <= 400
解法一:使用递归来做
按照灵神的说法,这种动态规划问题,也可以转化为类似子集性回溯的思想:分为
选或不选、枚举选哪个的问题所以我们可以先从递归的角度考虑,这里又可以参考一点代码随想录的思维
- 递归逻辑构建
- 首先考虑递归函数的返回值和参数
- 返回值
- 这题不同于回溯,回溯一般返回值是void,这是因为回溯过程中直接处理的是ans,一般在ans中添加答案即可
- 这题与其说像是回溯,倒不如说更像是
DFS二叉树遍历,它的返回值需要进行处理,所以设为int类型 - 参数:参数就是int类型,表示当前在处理的是第
i个房屋 - 考虑边界条件
- 边界条件就是如果当前第
i个房屋中,i的值小于0,很明显需要退出,返回值0 - 考虑单层递归
- 单层递归中我们选择了选或不选的思路,所以大致写出代码如下:
- 然后需要考虑返回值的情况,返回值就是对选或不选情况的结合处理:返回其最大值
Math.max(lastCnt, lastBefCnt);
- 为避免时间复杂度过高,使用记忆化搜索:
- 我们知道在处理中间过程的时候,选或不选两个分支有可能遇到相同的递归情况,这种情况就需要进行缓存处理,将第
i个房屋的情况缓存
结果就是如下情况:
解法二:使用递推
灵神将这个逻辑叫做递推,所谓递推其实就是大家说的状态转移方程
为什么叫递推?因为这个思路就是递归的思路,但是只选取归的部分,关系转换如下
- 将递归中return的表达式转为状态方程,使用一个数组
f来存储每次转换的状态 - 注意为了不产生负数下标,一般需要将数组
f的个数设置为n+2;
- 这个结构还可以优化,可以将一整个
f数组进行存储的方式变成仅使用两个变量,在进行状态转移的时候就是这两个数组值的变换
但我不习惯用递推,还是习惯递归
解法三:动态规划
python用来写动态规划很方便,现在又喜欢动态规划了
完全平方数
给你一个整数
n ,返回 和为 n 的完全平方数的最少数量 。完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,
1、4、9 和 16 都是完全平方数,而 3 和 11 不是。示例 1:
示例 2:
提示:
1 <= n <= 104
解法:记忆化递归
这类题型果然我还是喜欢使用记忆化递归的方法,使用递推的方式我完全用不来,递推方式中间有很多奇怪的检查点,会让我不由思考为什么需要这样写
相比较来说递归就好多了,本次0-1背包思路如下:
- 把输入的参数n看作是由一个平方数组成的数组中取值,每次取值获得的value是1
- 需要求出取值后恰好等于n(target)的最小价值和
- 很明显的0-1背包变形,使用python进行比较简便的书写
- 注意如果是使用其他语言,记得构造memo数组进行记忆化
- 注意点:
- 输入
isqrt(n)能作为i值,这样不需要构造一个平方和的weight数组,直接进行比较即可 - 有点类似传了一个自然数数组进去,然后进行map
- 注意这里取值是以1结束,不像之前还能取0值,所以说递归的边界条件是:
零钱兑换
给你一个整数数组
coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回
-1 。你可以认为每种硬币的数量是无限的。
示例 1:
示例 2:
示例 3:
提示:
1 <= coins.length <= 12
1 <= coins[i] <= 231 - 1
0 <= amount <= 104
解法:记忆化递归法
注意的是,在这种题目中不能直接使用Java中的最大值,因为在后面+1操作的时候会发生整数溢出
python版本
单词拆分
给你一个字符串
s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
示例 2:
示例 3:
提示:
1 <= s.length <= 300
1 <= wordDict.length <= 1000
1 <= wordDict[i].length <= 20
s和wordDict[i]仅由小写英文字母组成
wordDict中的所有字符串 互不相同
- 解法1
- 是用回溯的方法,从wordDict中进行查看,看是否可以组成一个word
- 解法2
- 也是回溯的方法,记忆化递归,但是着重点不一样,这个着重点在于从word开始,看其是否存在于Wordict中
- python版本
最长递增子序列
给你一个整数数组
nums ,找到其中最长严格递增子序列的长度。子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,
[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。示例 1:
示例 2:
示例 3:
解法
这个只能硬背了,我感觉能理解但是理解的不全面